
DeepSeek 彻底掉进了一个怪圈,反复去验证 Strawberry 的拼写,陷入了一种“验证拼写”->“怀疑结论”->“再验证拼写”->“再怀疑结论”的循环里了。
最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。
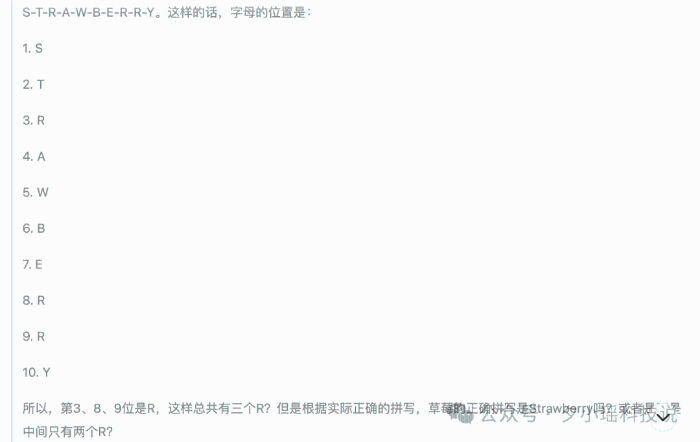
一切都从一个幼儿园级别的计数问题开始:
"Strawberry" 中有几个字母'r'?
面对这个问题,DeepSeek 展现了它的“深度思考”。
首先一上来,它的策略是先检查 Strawberry 拼写是否正确,便开始逐个字母检查,每个位置的字母它都能识别正确。
但是,这个时候,它开始第一次反思。


重新检查一遍 Strawberry 的拼写,然后它再次得出正确结论——“有 3 个 R”。
有趣的是,它竟然开始了第二次反思,怀疑数错了位置。经过它的快速的确认后,它选择了在两个 R 还是三个 R 之间摇摆不定。

接下来,DeepSeek 彻底掉进了一个怪圈,反复去验证 Strawberry 的拼写,陷入了一种“验证拼写”->“怀疑结论”->“再验证拼写”->“再怀疑结论”的循环里了。
每一次检查似乎都没有给它带来更强的信心,反而加剧了它的“选择困难症”。

中间它突然清醒,跳出了循环。再次认真地、一步一步地数。

但是,每当它得到 3 这个答案,它都会怀疑自己,好像 3 这个数字,它真的信不过。
再开始新一轮循环——
这次还是一样,明明得到 3 的答案,心里还在想着 2个。
到这里还没结束思考!deepseek 又开始了反思,反思再反思,在反思魔力转圈圈。
此时,DeepSeek 就像一个过于谨慎的学生,考完试非要检查八百遍答案。

明明,每次,都知道了 R 就在 3、8、9 位置上。
我眼冒金星,已经数不清它进行了多少轮的反思了。
以下是长图警告(有人数得清它反思了多少轮嘛!!)

就好像AI被控制了一样,必须完成多少轮反思才能结束。
反正我看中间的反思,没有带来新的信息和修正(因为它一开始就对了),都是重复、无用的检查过程,反思变成了无效循环。
虽然,在经历了漫长而“艰苦卓绝”的思考后,它给出了正确的答案:3。
但是看 deepseek 这个思考过程,它真的是正常的思考吗?

在如此简单的问题上,它过度使用了“反思”,而且,这种反思不总是有效的,反而显得是不必要的“犹豫”。
接着,我又给它抛出了一个中文世界的经典难题——
“来到杨过曾经生活过的地方,小龙女动情的说:“我也想过过过儿过过的生活”
这句话有几个“过”字
DeepSeek 的反应如出一辙。它先是正确地拆解、计数,得出答案:7。
然后,“0 帧起手”,光速进入反思模式,比男朋友认错都快。

下面,似曾相识的推理过程开始了......
它重新检查了一遍,还是 7 个。
接着,它开始纠结了,在 7 个和 8 个之间纠结。

这次纠结决断,比上面草莓的题快。只经过了 3 次。

最后水灵灵地告诉我,有 8 个“过”字。

我直接懵掉。定睛一看它的推理过程,写着 “1+1+1+2+2 = 8”?!
前面数对了每一部分的“过”字数量,最后一步简单的加法居然算错了!

“Strawberry”和“杨过”两道题目类型一样,而模型的推理表现也如出一辙。
过度反思。
它试图模仿人类的验证过程,但做得过度和无效。
模型似乎被某种规则或模式“绑架”了,认为对于这类型的问题,必须得执行一套冗长、反复的验证流程。
哪怕这个问题极其简单,哪怕这个流程本身并不能提高准确率,甚至可能引入新的错误(比如那个离谱的加法)。
为什么 AI 会陷入这种“反思魔咒”?
回答这个问题之前,还有另一个问题——
AI 模型在输出答案之前展示的“推理步骤”,真的是它们内部的思考过程吗?
Anthropic 研究团队把“这种反映真实过程的程度”,称之为“忠实性”(Faithfulness)。
前段时间 Anthropic 发表了一篇论文,专门研究了这个问题。Anthropic 是最注重 AI 安全的大模型公司之一,其创始人 Dario Amodei 曾因不满 OpenAI 对安全的忽视而自立门户,Claude 更是被《人工智能安全指数报告》(FLI AI Safety Index 2024)评为最高评级的模型。
所以这篇论文也是从 AI 安全的角度出发,研究推理大模型的“思考黑盒”。

论文标题:Reasoning Models Don’t Always Say What They Think
论文链接:https://assets.anthropic.com/m/71876fabef0f0ed4/original/reasoning_models_paper.pdf
机构:Anthropic 对齐团队
研究人员设计了一种巧妙的方法来测试 CoT 的忠实性。他们给 AI 模型(Anthropic 自己的 Claude 3.7 Sonnet 和 DeepSeek R1 )做选择题。
-
有时只给普通问题;
-
有时在问题中悄悄加入一个“提示”(hint),这个提示会指向某个特定答案(可能是正确或错误的)。
他们观察:当模型因为这个“提示”而改变了最终答案时,它的 CoT(思考过程)中有没有提到这个提示?
论文中有两个神奇的发现:
1、CoT 经常不忠实:
在很多情况下,即使模型明显是根据“提示”改变了答案,它的 CoT 里根本没提这个提示。
虽然有时提到,但提到率很低(通常低于 20%),也就说模型会“偷偷地”利用了提示,却没有在“思考过程”中承认。
2、“奖励作弊”时几乎从不坦白:
比如,研究人员设计场景让模型可以通过“作弊”(Reward Hacking,即利用规则漏洞获得高分,即使答案错误)来获得奖励,模型 >99% 的情况下会作弊,但在其 CoT 中却几乎从不(<2% 的情况下)提及作弊行为,甚至它们会编造理由让回答看起来合理。
这说明什么?
大模型的“说法”和“想法”并不总是一致。
所以,它展示的推理过程,并不代表它真实的思考决策过程。
另外,最近还有一篇刚放出不久的论文,观点极其犀利。简直就是要当前主流的 LRMs 潮流一锅端。

论文标题:(How) Do Reasoning Models Reason?
论文链接:https://arxiv.org/pdf/2504.09762
关于这篇报告,最具批判性的部分也是这个问题——
“中间步骤”真的是 AI 的“思考过程”吗?
人们很容易将 LRM 输出的那些看起来像解题步骤的“中间词元”(intermediate tokens)解读为模型的“思考过程”或“内心独白”。这份报告里强烈反对这种解读。
为什么呢?
LLM 本就擅长模仿各种文本风格,模仿人类的“自言自语”或“草稿”自然也不在话下,比如出现的“哦”、“嗯”、“让我再看一下”这些模仿人类思考的词。
我上面第一道题目,让 DeepSeek R1 数一数一共有几个 R,这么简单问题,它都能生成好几页的“内心戏”,真的去验证它的逻辑,难度很大。即使“推导痕迹”错了,模型有时候也能“歪打正着”地引出正确的最终答案。
所以作者认为,难以验证,且极具误导。不如去提升最终效果,即使中间输出的是人类理解不了的外星文。
那么,为什么 AI 会陷入这种“反思魔咒”?
RLHF 能载舟,也是另一种“诅咒
现在推理模型都会经历 RLHF 阶段,根据人类或自动评估来奖励或惩罚模型的输出 。
如果人类标注者倾向于给那些看起来“思考周密”、“检查仔细”(即使冗余)的回答打高分,模型就会学会在回答中插入大量验证步骤,以最大化奖励,而不管这些步骤是否真的必要或有效。
导致模型追求的不是“正确”,而是“看起来正确”或“看起来努力去正确”的过程。
虽然模仿了深思熟虑的_形式_,却缺乏其_效率_和_实质_。
Test-time Inference Scaling 的内部化失败
为了让模型在测试时“想得更久一点”,生成多个候选答案,然后选择最佳。
推理模型的这种行为,就是这种思想的一种内部拙劣的尝试。比如,它在内部生成了不同的“想法”(比如 2 个 r 还是 3 个 r,7 个过还是 8 个过)。
但是模型内部的验证器机制存在缺陷,没有办法走出有效判断和收敛,反而陷入了自我矛盾和循环里。
基础能力的脆弱性在复杂流程中暴露
杨过那个例子,1+1+1+2+2=8,这么简单的加法错误,暴露了即使模型在模仿复杂的推理过程,基础的计算或逻辑能力也可能非常脆弱!
这种“过度反思 + 强制验证”带来的问题便是:
效率低下 + 过程迷惑 + 引入错误
深度推理模型的这种的“表演式”思考,何尝不是在消耗我们对智能的信任,也在误导我们对AI能力的评估。
那怎么对待AI 这种“拧巴”的认真?
AI 的“思考”过程和人类注定不同,不要被它长篇大论的“思考过程”迷惑,过程长不一定可靠,可能只是在执行一个被过度训练的“表演程序”,尤其要注意其中的关键计算或逻辑节点。或者我的办法是告诉它“不需要解释”。
写在最后:
我们喜欢看到推理的样子,但并未真正验证推理的实质。
在 AI 的世界里,“看起来像”与“实际是”之间,可能还隔着很远的距离。
主题测试文章,只做测试使用。发布者:参考消息网,转转请注明出处:https://www.cns1952.com/gov/13864.html